This post was originally published March 17, 2019 on Medium.
Taipei Ethereum Meetup presentation
Vitalik recently presented his thoughts on Rollups and the problem of Data Availability as related to Layer 2 solutions in both Ethereum 1.0 and 2.0. His talk contains some fascinating constructions that will likely see further iterating from teams in the space. This a crucial area of research because trust-minimised blockchain scaling mechanisms are still sorely needed for projects looking to grow their userbase. If you have the time I recommend listening to the full talk.
PREVIOUS RESEARCH
The foundational concepts that this talk builds on first surfaced in an August 2018 post by Vitalik, crediting “availability engines” to Justin Drake. In September 2018, an ETHresearch post expanding on the topic received significant discussion. In January 2019 a collaboration between EF researchers and Matter Labs produced a proof of concept called Ignis on the Rinkeby testnet. Here’s the original post from the teams and a Trustnodes interview / demo.
Here is a great talk from ETHDenver 2019 by Alex Gluchowski and Kent Barton with more details on the Rollup mechanism: Scaling With Zero Knowledge. There is also a good exploration on the differences between SNARKs and STARKs.
Finally, it looks like Matter Labs is continuing their work on scaling via snarks thanks to an EF grant — check the announcement here along with more resources.
I’ve typed up a rough transcript of Vitalik’s talk below that tries to capture the essence of each section. Hopefully people find this useful.
BACKGROUND / MASTERCOIN
- Here’s a new kind of L2 construction — not the same as L2 for scalability (plasma / state channels) — which uses BC as a place for data storage and not computation. Computation can be done with zk-snarks.
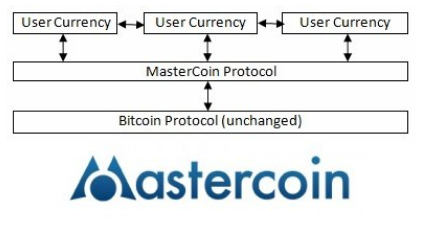
- Some history: think of Mastercoin as a meta protocol on top of BTC. Defines a different set of rules for interpreting tx. BTC is data store but not state execution. Special txs can be denoted by a flag.
- Drawbacks to Mastercoin: Not light client friendly (need BTC blockchain and Mastercoin node). Activity in MC protocol cannot influence BTC chain, which limits overall functionality
- Now we have ETH 1.0 and soon™ we will have ETH 2.0 — can we do something similar to Mastercoin?
ZK ROLLUP
- ZK rollup (not ignis, not ignis plasma) can help with scalability by a factor of 30 today, higher in the future. How it works: Onchain contract only stores one value: the merkle root of a merkle tree
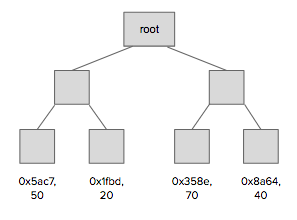
- Users send txs, which are gathered by a special actor called a relayer and put into a zKsnark. Publishes previous state, new state which includes transactions that were bundled together
- Is this similar to Plasma? (both are contracts that hold merkle roots) Difference is that Plasma needs complex exit games / withdrawal periods in order to deal with possibility of malicious operators (data availability)
- No data availability problem with zK Rollup because all transactions are published to chain, without signatures
- 13 bytes per publish X 68 gas per byte = 884 gas versus current cost of 21k for simple tx currently
- Instead of having ETH mainchain verify each signature transaction, the zKsnark proves tx validity. Computation and storage is moved offchain. Merkle root stays onchain. This avoids central operator / relayer. Because the data is published onchain, anyone can verify.
- This can be improved by not including nonce, removes 2 bytes (11 bytes per publish X 68 gas per byte = 748 gas)
- Note: instant deposits and withdrawals. Withdrawals: Coins are moved from their merkle Branch to mainchain and then merkle root updates. A deposit would be the inverse, but additionally gives the user an account ID. There would possibly be many floating around.
- This construction could increase simple payments from 15 tx/s to 500 tx/s, relatively safely.
- One takeaway from Stanford 1.x workshop (recorded livestream) was that data is overpriced relative to other operations. Though there are concerns with state, adding 1 kb to the blocksize will not make things much worse. Possibility that in Istanbul the gas cost of simple tx will be reduced, thus increasing throughput of ETH 1.x to over 1000 tx/sec
TAKING ROLLUP FURTHER
- Rollup should be able to support more complex state transitions, including things like Uniswap, high performance exchanges, multiple tokens, privacy preserving computation, ENS — all using “SNARK + publish tree details” paradigm.
ZK ZK ROLLUP (Bose–Einstein condensate 🙃)
- Basic idea: take ZK rollup but with mini version of zcash inside. (primer on zCash: users publish txs with SNARKs saying “I have a valid spend certificate for some coin hash in the state. Here is a new coin hash”
- zCash, continued — user has secret S, coin hash: h(s + 1), spend certificate: h(s + 2). SNARK proves that the spend certificate belongs to an existing coin, but not which one. Verification function should also check that spend certificate has not been revealed
- The relayer wouldn’t be publishing txs, it would be publishing receipts (105 bytes X 68 gas = 7140 gas per tx). Here we put a single SNARK which verifies that for every single tx included there is a SNARK attached (one level of recursion). Verifying SNARKs onchain, it would require 500k gas
BEACON CHAIN — PHASE 1
- What if we wanted to do more? Enter Beacon Chain phase 1 of ETH 2.0. Shard chains as data-only chains means 2.8 MB/sec of data availability
- Each zK zK rollup is 105 bytes / meaning 27k privacy preserving transactions / sec if fully consuming the 2.8 MB. If we don’t care about privacy then that 27k increases by a factor of 10
- Get rekt scamcoins LOL VB can’t even choose which is the worst at TPS claims
- The barrier is that these systems rely on data and computation (albeit a tiny amount). ETH 2.0 (Phase 1) doesn’t have computation but lots of data, whereas ETH 1.0 has computation: Let’s bridge the two.
ETH2 IN ETH1 LIGHT CLIENT
- ETH 2.0 research team has spent a lot of time making the 2.0 architecture light client friendly
- Requires 80kb of merkle branches per 9 days when persistent committees switch (also could be amortised over 9 days), plus 500 bytes per header
- Would need BLS-12-381 precompile in ETH1 clients
- ETH 1 chain could be computation layer that hooks into 2.0 chain, requires that data for roll-up schemas be published on 2.0 chain
OTHER USES FOR SCALABLE DATA AVAILABILITY ENGINES
- Plasma chains w/ much more frequent commitments, Dapps storing messages onchain, blockchain protocols w/ independent (“sovereign”) state transition functions piggybacking on Ethereum for Data availability
SPEEDING UP CROSS-SHARD TRANSACTIONS
- Weakness of current sharded design: communication between shards has a delay (waiting for crosslinks, ~6 minutes)
- The rough proposal to get around this latency is a mechanism that allows one shard to see the roots of another shard. This would probably work most of the time
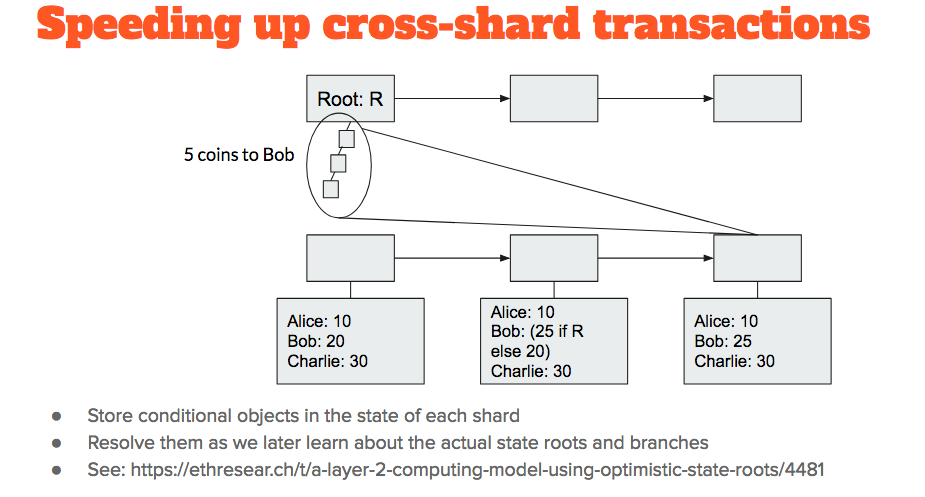
- A quick exploration for when users want to transfer tokens between shards: they can publish tx to smart contract with root ( containing an expected token transfer), along with a security deposit
- “merkle root of shard is 0x12345 and I agree to lose 100 ETH (the deposit) if this claim is wrong”
- In the context of the registry storing token balances, user who posted 100 ETH deposit (while waiting for x-shard transaction to come through) then has their balance updated to a conditional state: if state root claim is correct I have x + transferred amt, if not correct I only have original amount (minus forfeited ETH deposit)
- Think of it as quantum superposition inside of SC (storing both states / both possibilities). Only resolved once contract becomes aware of state root of original shard via crosslink
- This superposition can then be transferred between users without them knowing (wallets would show optimistic values until ~6 minutes later and the crosslink were actually sent through)
GENERAL PURPOSE PRIVACY
- ZEXE: a UTXO based system that preserves privacy
BENEFITS OF LAYER 2 COMPUTATION
- Philosophically, Layer 1 does not need to be overly complex to optimise properties — block-times, x-shard communications, x-shard synchronous messaging support, privacy, etc
- Theoretically ETH 2.0 Phase 3 might be sufficient forever, no need for super quadratic sharding
- Exception would be increasing shards or updating cryptography
- Other blockchains have made this claim but the reality is once you have scalable data availability and enough expressivity at least to verify zKSnarks and state transitions (minimum threshold for power and complexity)you can build all necessary L2 on top
- L1 might get harder and harder to change, but this is fine for computational L2 if they are on top of scalable data availability (2.8 mb / sec)
QUESTIONS
Q: Doesn’t L2 stuff preclude turing complete languages / won’t work with zKsnarks?
There’s a difference between math definition of TC vs what crypto community means. Math: TC means computational lang. That are so general that you can’t tell when a computation will stop (Snark needs to know this beforehand)
Crypto: uses TC to mean expressive enough to make applications with complex internal state (plasma, makerdao, uniswap, verification engines for these L2) BTC can’t do these things, ETH can. ZEXE is UTXO based model but can as well.
TC is the wrong word but it is the case that you can do things that are expressive enough for constructing applications inside of zKsnarks.
Q: Should we be worried about the 30% hash rate loss during the bear market?
It is an issue but not something really to worry about. ETC (Ethereum Classic)has been attacked but only has 3% hashrate of ETH chain. If it becomes a significant concern then Phase 0 can be used as a finality mechanism for the 1.0 chain POW clients. 51% attack would then only allow censoring blocks, not reverting blocks
Q: There will always be competition between degree of decentralisation between base layer and Application layer. Does data availability and SNARKs always mean centralisation? [partially inaudible]
This new class of L2 is interesting - doesn’t need to solve for data availability issues. Centralisation can be reduced. Compare Plasma and Rollup: Plasma data availability problem means there needs to be an operator, who can then waste users time with 2 week coin lockup if malicious. Rollup has no data availability issue bc if a relayer disappears, another can quickly take their place. Possible harm is reduced, L2s like Rollup are part of the solution.
Q: Are you considering two phase commit protocol [inaudible] when doing cross-shard communication?
Contract yanking helps to solve train and hotel problem. (interacting with 2 objects on different shards) Should the ETH chain support synchronous on L1? No, it introduces too much complexity.
Right now, between two crosslinks you can calculate the state transitions in a shard as being a function of the data in a shard and the beacon chain. Doesn’t depend on what happens in other shards
Having synchronous cross-shard calls breaks this invariant, makes state calculation game much more complicated, though you could implement a L2 like Rollup that would help support synchronous cross-shard calls.
Q: What is the relationship between “third-party” L2 solutions (Celer) and other Ethereum L2 solutions?
Celer is a L2 that provides its own data availability solution, Plasma also does this. Rollup does computation offchain and has data availability handled onchain. Has different tradeoffs.
Find me @trent_vanepps on twitter for discussion or corrections. ✌